1.安装了pytorch的python虚拟环境
2.cmake文件
cmake_minimum_required(VERSION 3.22)
project(paperscuda LANGUAGES CUDA CXX)
set(CMAKE_EXPORT_COMPILE_COMMANDS ON )
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(CMAKE_CXX_EXTENSIONS ON)
# use cudnn for cuda >12.0
# set(CAFFE2_USE_CUDNN 1)
set(CAFFE2_USE_CUDNN ON)
# if(MSVC)
# add_compile_options("/source-charset:utf-8")
# add_compile_options("/execution-charset:gbk")
# endif(MSVC)
set(Python_ROOT_DIR "${CMAKE_SOURCE_DIR}/.venv")
# find python Interpreter
# find_package(Python3 COMPONENTS Interpreter)
find_package(Python COMPONENTS Interpreter Development)
message(STATUS "Python interpreter: ${Python_EXECUTABLE}")
message(STATUS ${Python_INCLUDE_DIRS})
include_directories(.)
set(Torch_DIR ${Python_ROOT_DIR}/Lib/site-packages/torch/share/cmake/Torch)
find_package(Torch REQUIRED)
message(STATUS ${CUDA_nvrtc_LIBRARY})
add_executable(main main.cu)
# add_executable(matmul matmul.cu)
message(STATUS ${TORCH_LIBRARIES})
# lib link
target_link_libraries(main ${TORCH_LIBRARIES})
# add dll to binary
# 定义lib文件夹路径
set(LIB_DIR ${Python_ROOT_DIR}/Lib/site-packages/torch/lib)
# 设置目标二进制输出目录
set(BINARY_DIR ${PROJECT_BINARY_DIR})
# 查找所有 .dll 文件,排除 .lib 文件
file(GLOB DLL_FILES "${LIB_DIR}/*.dll")
# 添加自定义命令,在 POST_BUILD 阶段执行
add_custom_command(TARGET main POST_BUILD
COMMAND ${CMAKE_COMMAND} -E make_directory ${BINARY_DIR} # 确保目标目录存在
COMMAND ${CMAKE_COMMAND} -E copy_if_different ${DLL_FILES} ${BINARY_DIR} # 复制所有 .dll 文件到目标目录
)
# add_library(paperscuda SHARED library.cu)
# set_target_properties(main PROPERTIES
# CUDA_SEPARABLE_COMPILATION ON)
main.cu
#include <iostream>
#include <cuda_runtime.h>
#include "device_launch_parameters.h"
#include <torch/torch.h> // libtorch
using namespace torch; // libtorch
using namespace std;
__global__ void matmul_gpu(float *A, float *B, float *C, int m, int k, int n)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < m && col < n)
{
float sum = 0.0f;
for (int l = 0; l < k; l++)
{
sum += A[row * k + l] * B[l * n + col];
}
C[row * n + col] = sum;
}
}
int main()
{
cout << torch::cuda::is_available() << endl;
cout << torch::cuda::cudnn_is_available() << endl;
cout << torch::cuda::device_count() << endl;
return 0;
}一个合适的cmake编译输出文件:
[main] 正在配置项目: paperscuda
[proc] 执行命令: "C:\Program Files\CMake\bin\cmake.EXE" -DCMAKE_BUILD_TYPE:STRING=Debug -DCMAKE_EXPORT_COMPILE_COMMANDS:BOOL=TRUE --no-warn-unused-cli -SD:/GitHub/paperscuda -Bd:/GitHub/paperscuda/build -G Ninja
[cmake] Not searching for unused variables given on the command line.
[cmake] -- Python interpreter: D:/GitHub/paperscuda/.venv/Scripts/python.exe
[cmake] -- C:/Users/Administrator/AppData/Local/Programs/Python/Python310/include
[cmake] -- Caffe2: CUDA detected: 12.6
[cmake] -- Caffe2: CUDA nvcc is: C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.6/bin/nvcc.exe
[cmake] -- Caffe2: CUDA toolkit directory: C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.6
[cmake] -- Caffe2: Header version is: 12.6
[cmake] -- C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.6/lib/x64/nvrtc.lib shorthash is bac8224f
[cmake] -- USE_CUSPARSELT is set to 0. Compiling without cuSPARSELt support
[cmake] -- Autodetected CUDA architecture(s): 6.1
[cmake] -- Added CUDA NVCC flags for: -gencode;arch=compute_61,code=sm_61
[cmake] -- C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.6/lib/x64/nvrtc.lib
[cmake] -- torchtorch_libraryD:/GitHub/paperscuda/.venv/Lib/site-packages/torch/lib/c10.libD:/GitHub/paperscuda/.venv/Lib/site-packages/torch/lib/kineto.libC:\Program Files\NVIDIA Corporation\NvToolsExt\/lib/x64/nvToolsExt64_1.libC:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.6/lib/x64/cudart_static.libD:/GitHub/paperscuda/.venv/Lib/site-packages/torch/lib/caffe2_nvrtc.libD:/GitHub/paperscuda/.venv/Lib/site-packages/torch/lib/c10_cuda.lib
[cmake] -- Configuring done (8.6s)
[cmake] -- Generating done (0.0s)
[cmake] -- Build files have been written to: D:/GitHub/paperscuda/build
3.补充说明
1.关于find_package(Python3 COMPONENTS Interpreter)
导入torch需要查找到python解释器和库的位置(这来源于caffe需要借助python来计算库文件的hash值),在启用了virtualvenv时,我们希望找到venv的解释器地址。find_package(Python3 COMPONENTS Interpreter)可以帮助我们,但需要注意:
- find_package(Python3 COMPONENTS Interpreter)
- find_package(Python2 COMPONENTS Interpreter)
- find_package(Python COMPONENTS Interpreter)
这三项是不一样的,python3会加上3的导入变量后缀,所以在实际使用中,应该使用第三项,这和caffe使用了python变量前缀有关。
我们使用set(Python_ROOT_DIR "${CMAKE_SOURCE_DIR}/.venv")来帮助find_package找到解释器位置,对于不同的前缀,需要根据情况改写成Python_、Python3_或者Python2_。
2.关于英伟达12.0对某些组件修改
英伟达在cuda12.0后对NvToolsExt变为了头文件,而非库文件,解决这一问题直接下载cuda11.8进行单独安装即可。
3.关于cudnn等算子出现的问题
这些额外组件可能会出现以下状况:
[cmake] -- USE_CUDNN is set to 0. Compiling without cuDNN support
[cmake] -- USE_CUSPARSELT is set to 0. Compiling without cuSPARSELt support
在cuda>12.0时,观察caffe的cmake文件可以看到,需要设置:
# use cudnn for cuda >12.0
# set(CAFFE2_USE_CUDNN 1)
# set(CAFFE2_USE_CUDNN ON),值得注意的是,需要提前安装cudnn(将相关文件复制到cuda文件夹下)并配置相关Path变量:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\lib4.编译时出现的A single input file is required for a non-link phase when an outputfile is specified
出现的原因如下:
# if(MSVC)
# add_compile_options("/source-charset:utf-8")
# add_compile_options("/execution-charset:gbk")
# endif(MSVC)NVCC 不喜欢从 CXX 编译器传递的任何<font style="color:rgb(12, 13, 14);">/</font>标志
一个可能的设置是(或者不使用中文注释):
set(my_cxx_flags -DBOOST_ASIO_DISABLE_CONCEPTS /std:c++latest /await:strict /bigobj "/Zc:__cplusplus")
target_compile_options(${project} PRIVATE $<$<COMPILE_LANGUAGE:CXX>:${my_cxx_flags}> )5.关于运行时c10.dll等无法找到
这是因为使用了动态库dll,在target_link时只是把lib(lib在动态库只有符号表的作用,在静态库会在链接时全部链接)符号表加入进去了,运行时需要把运行库dll也加入到当前文件夹下
一个可以参考的指令如下:
# 定义lib文件夹路径
set(LIB_DIR ${PROJECT_SOURCE_DIR}/3rdparty/haikangsdk/lib)
# 定义目标二进制输出目录
set(BINARY_DIR ${PROJECT_BINARY_DIR})
add_custom_command(TARGET test POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_directory
${LIB_DIR}
$<TARGET_FILE_DIR:test>
)注意,需要找到所有dll文件才行
6.关于__gobal__非良构现象
添加相关头文件
#include "cuda_runtime.h"
#include "device_launch_parameters.h"关于cuda12.6和pytorch12.4
<font style="color:rgb(34, 34, 38);">undefined symbol: __cudaPopCallConfiguration</font>
在写的过程中会出现一些问题,包括但不限于代码检查报错,但确实能执行下去,主要是因为本文章使用的cuda为12.6,但是pytorch是通过12.4编译的,出现了不一致的问题。
引发异常:0xC0000005:读取位置0xFFFFFFFFFFFFFFFE时发生访问冲突
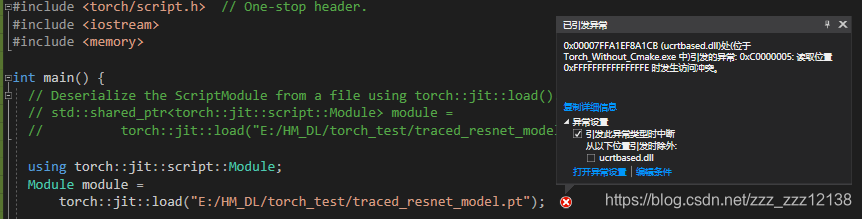
出现这个问题的原因和前面的“torch-NOTFOUND.obj无法找到”是一样的。也是因为下载的libtorch是release版本的, 却在debug下编译, 或者反之。
所以解决方法就是在release下编译release版本的libtorch,用debug编译debug版本的libtorch。
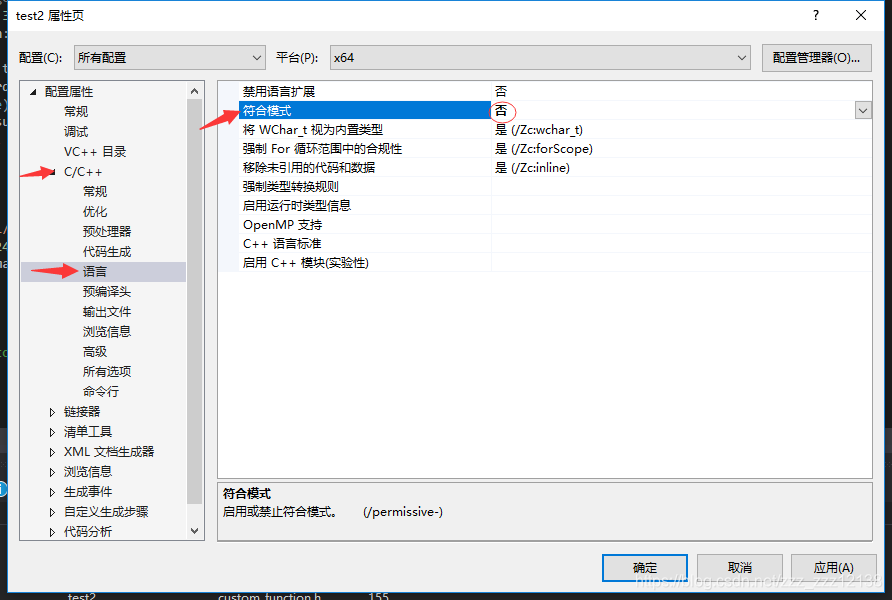
error :c2872 std 不明确的符号
解决方法:将 属性》C/C++》语言》符合模式 改为否,问题解决。